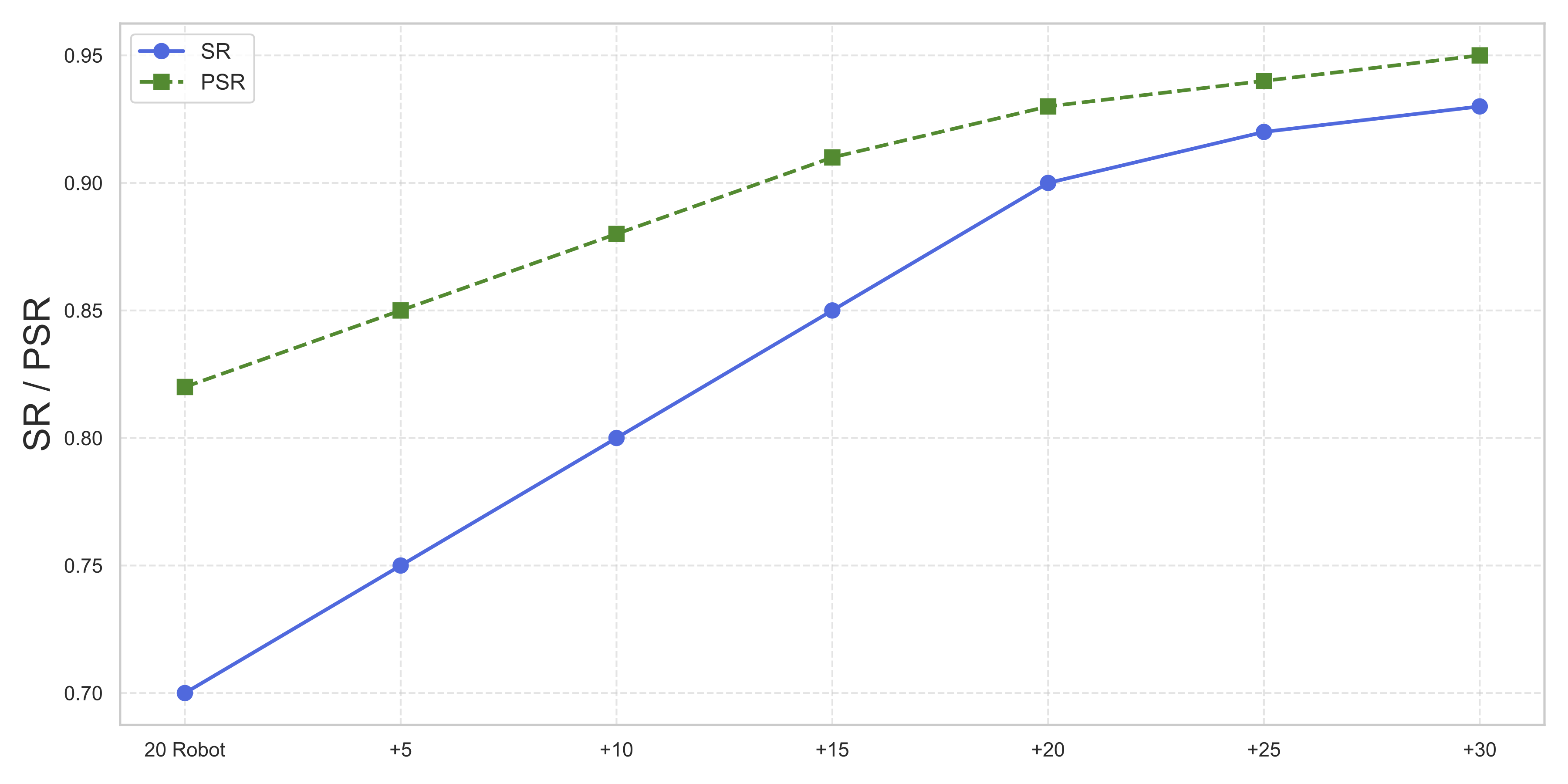
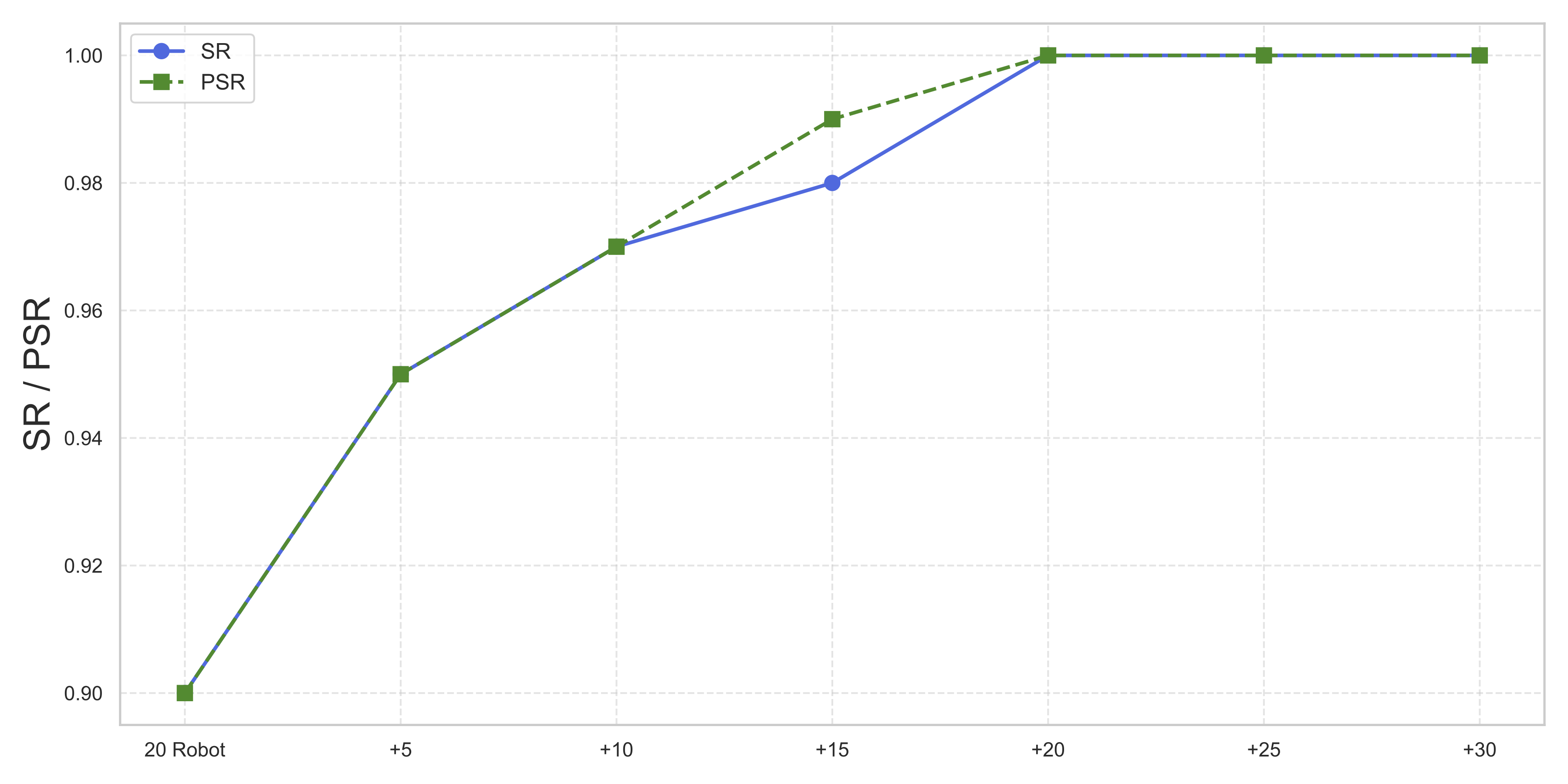
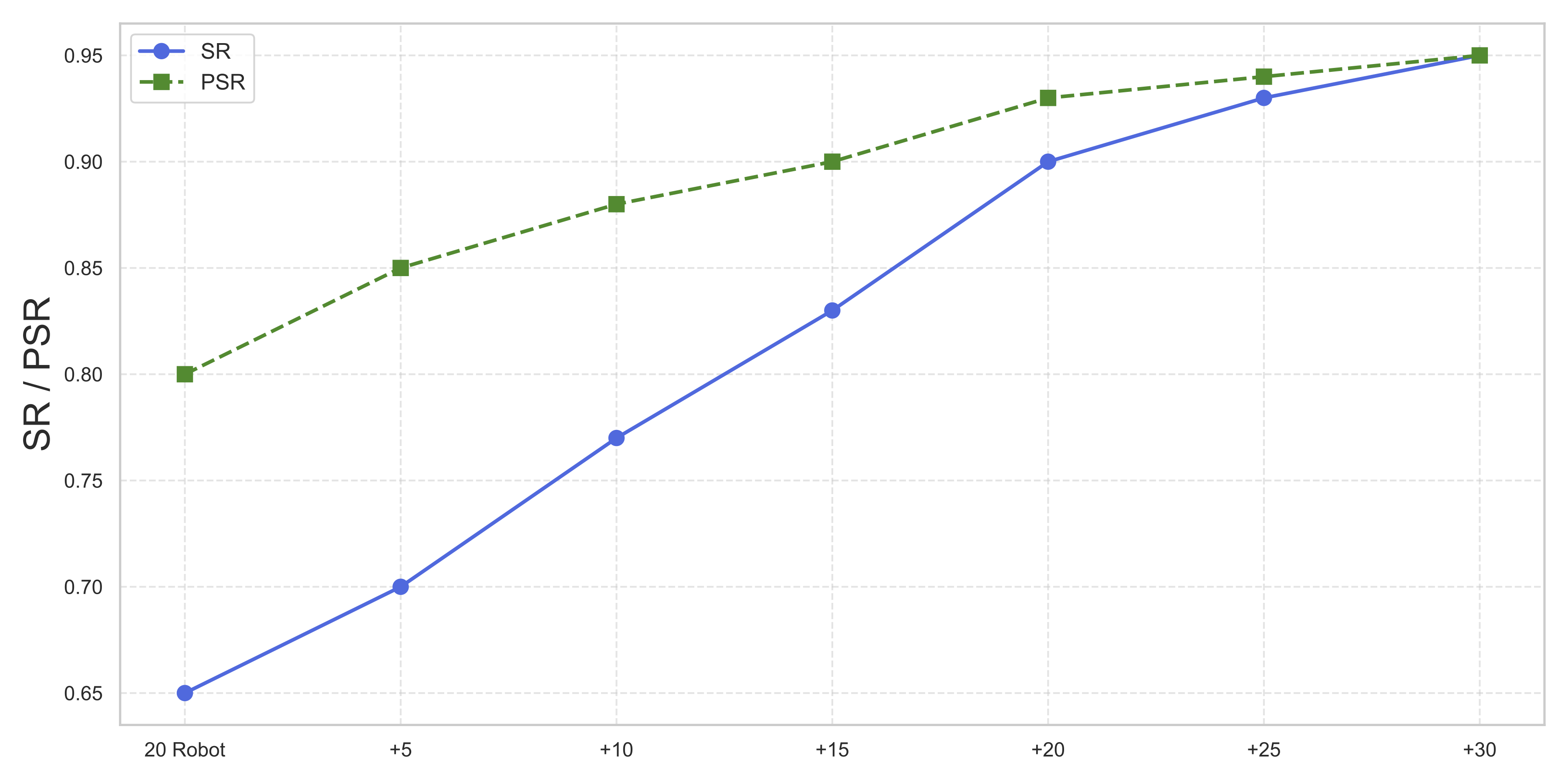
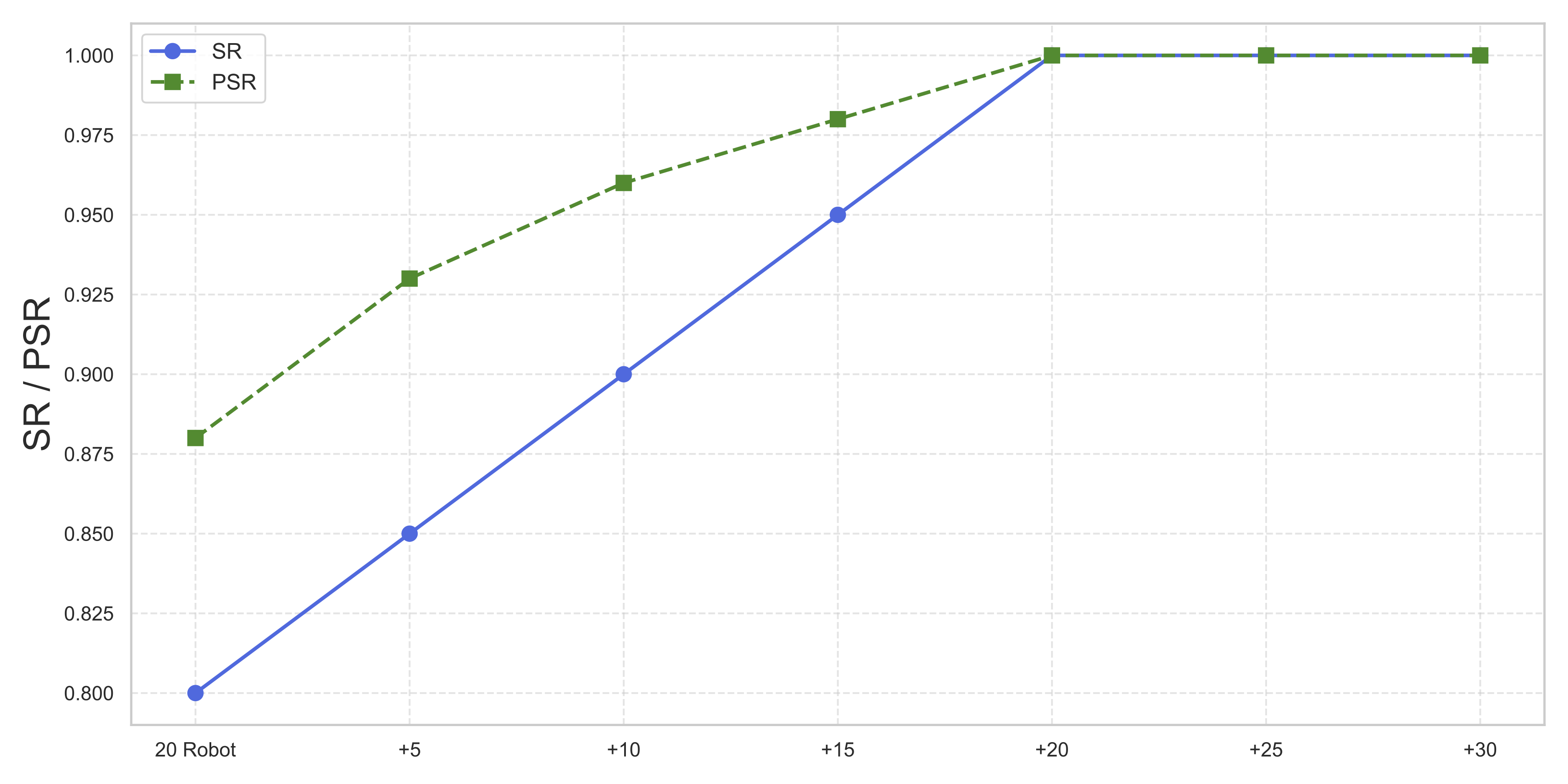
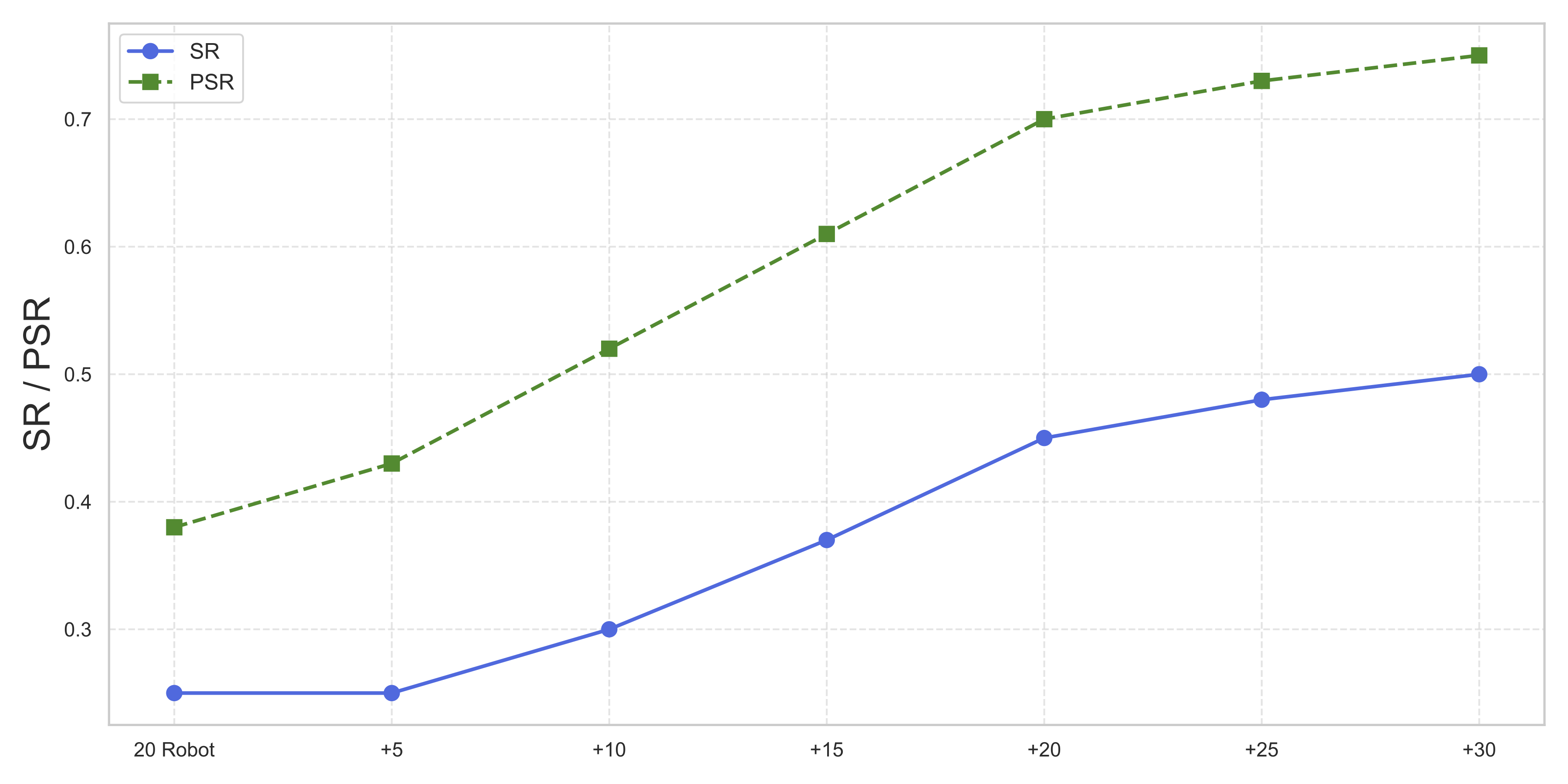
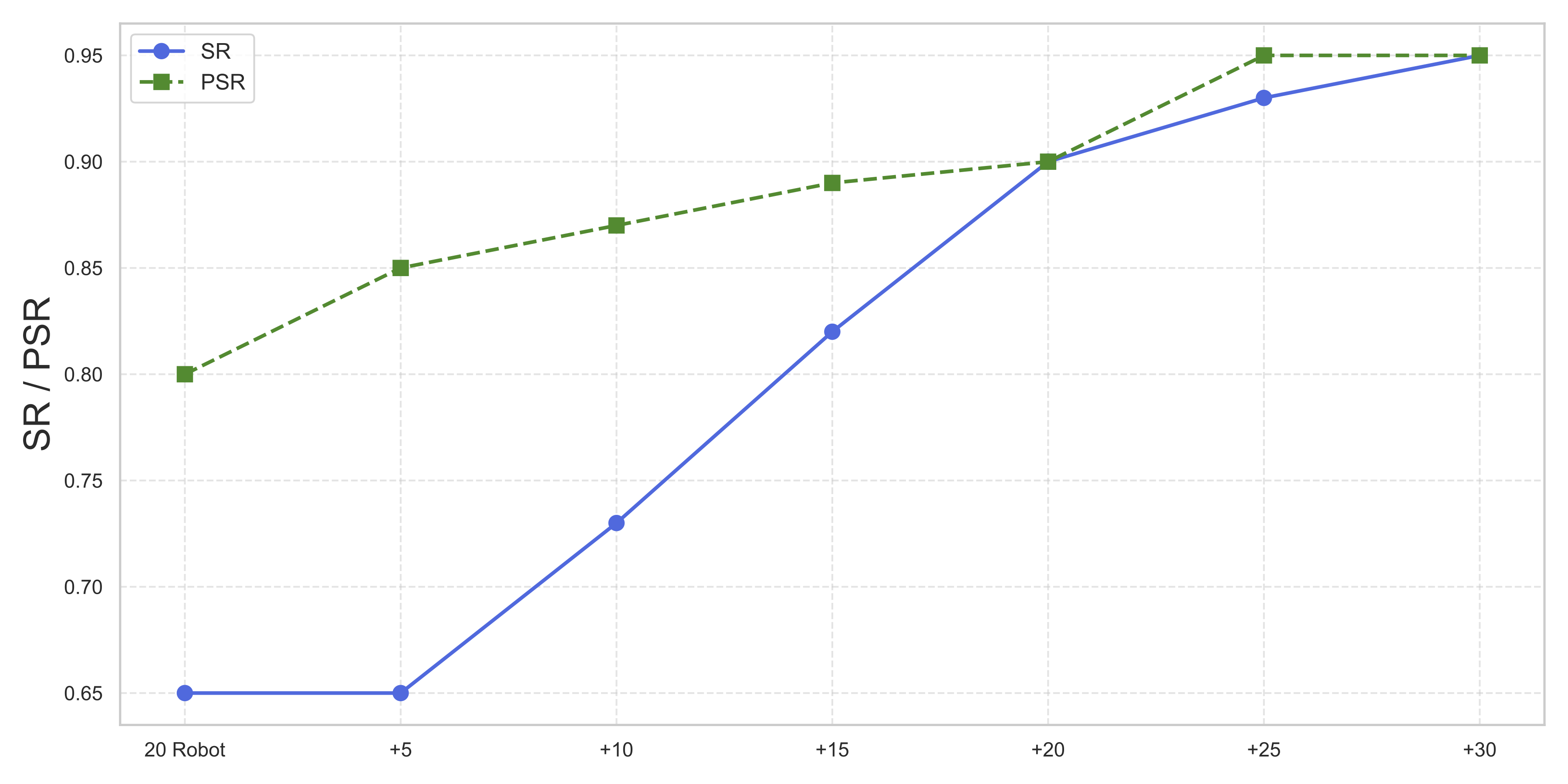
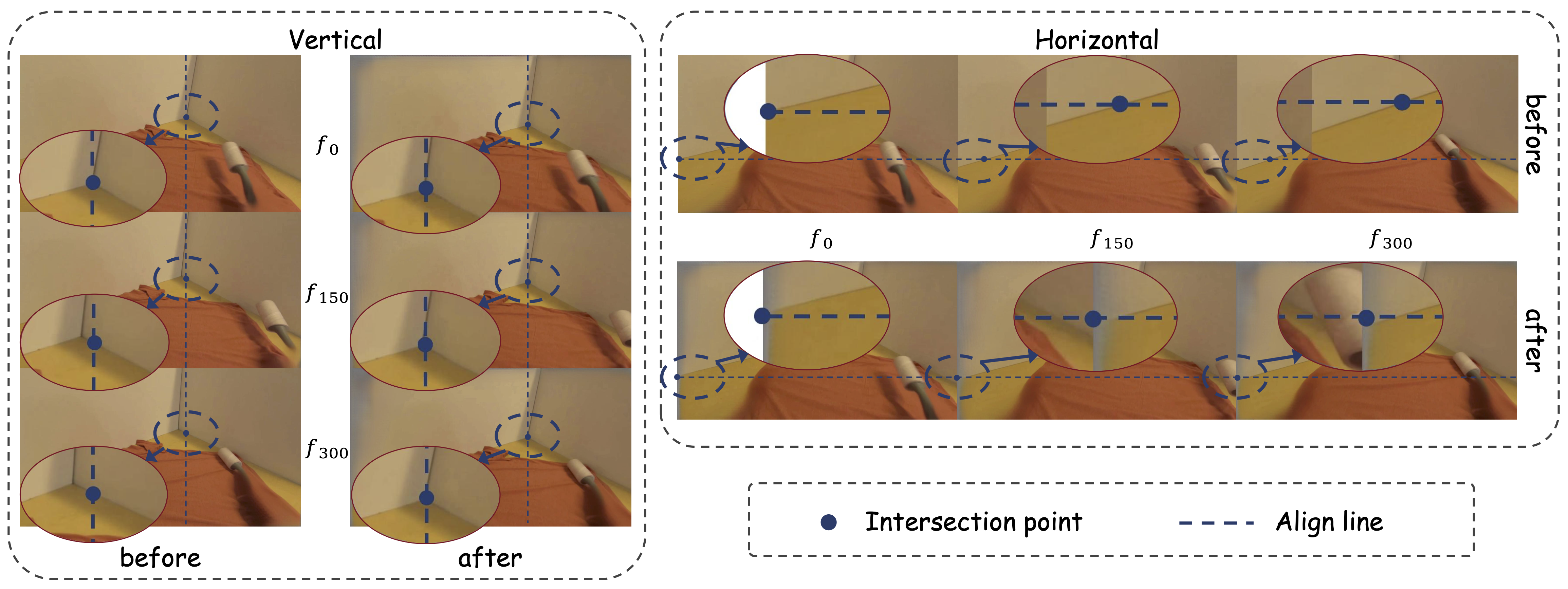
Method
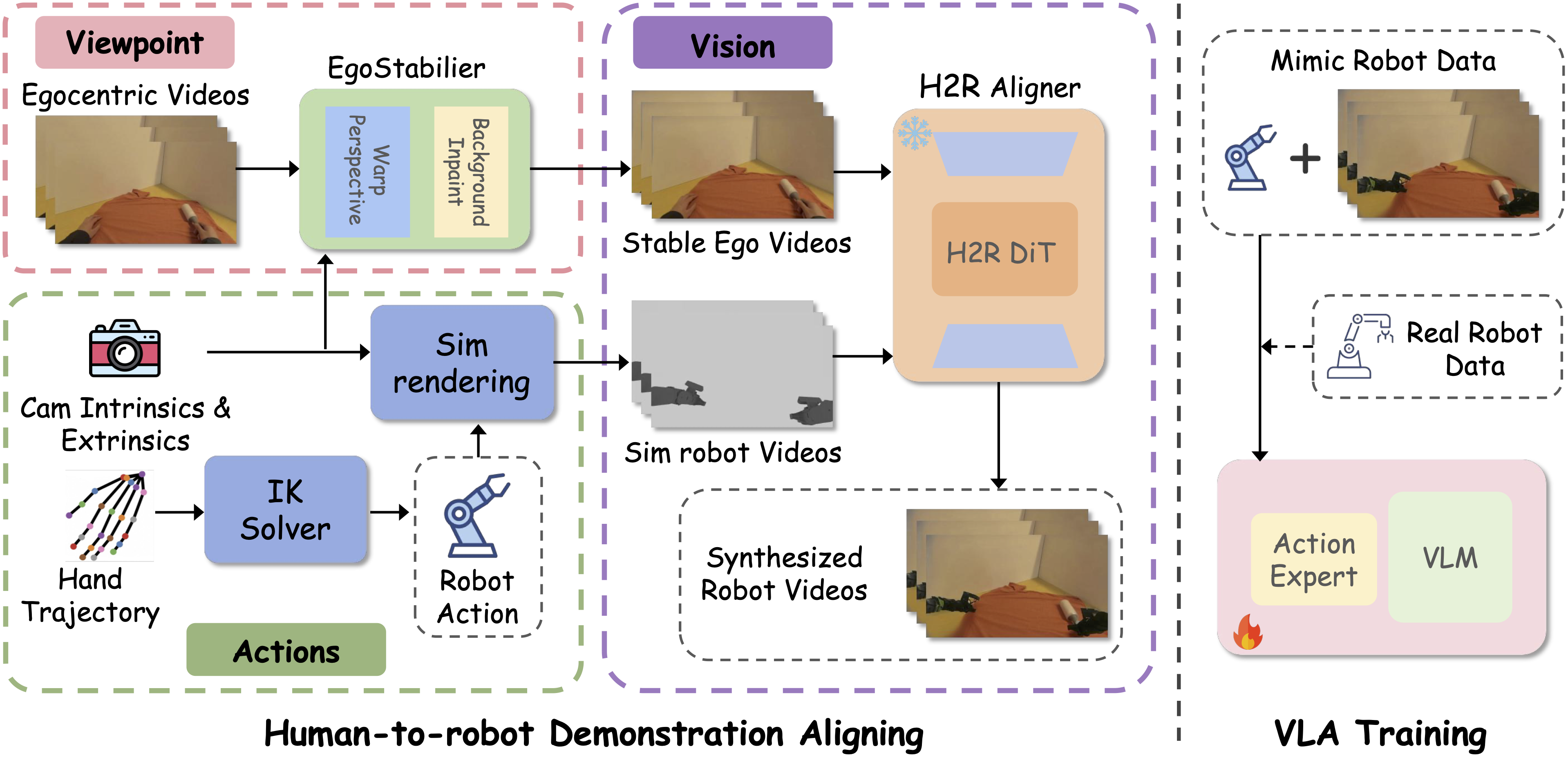
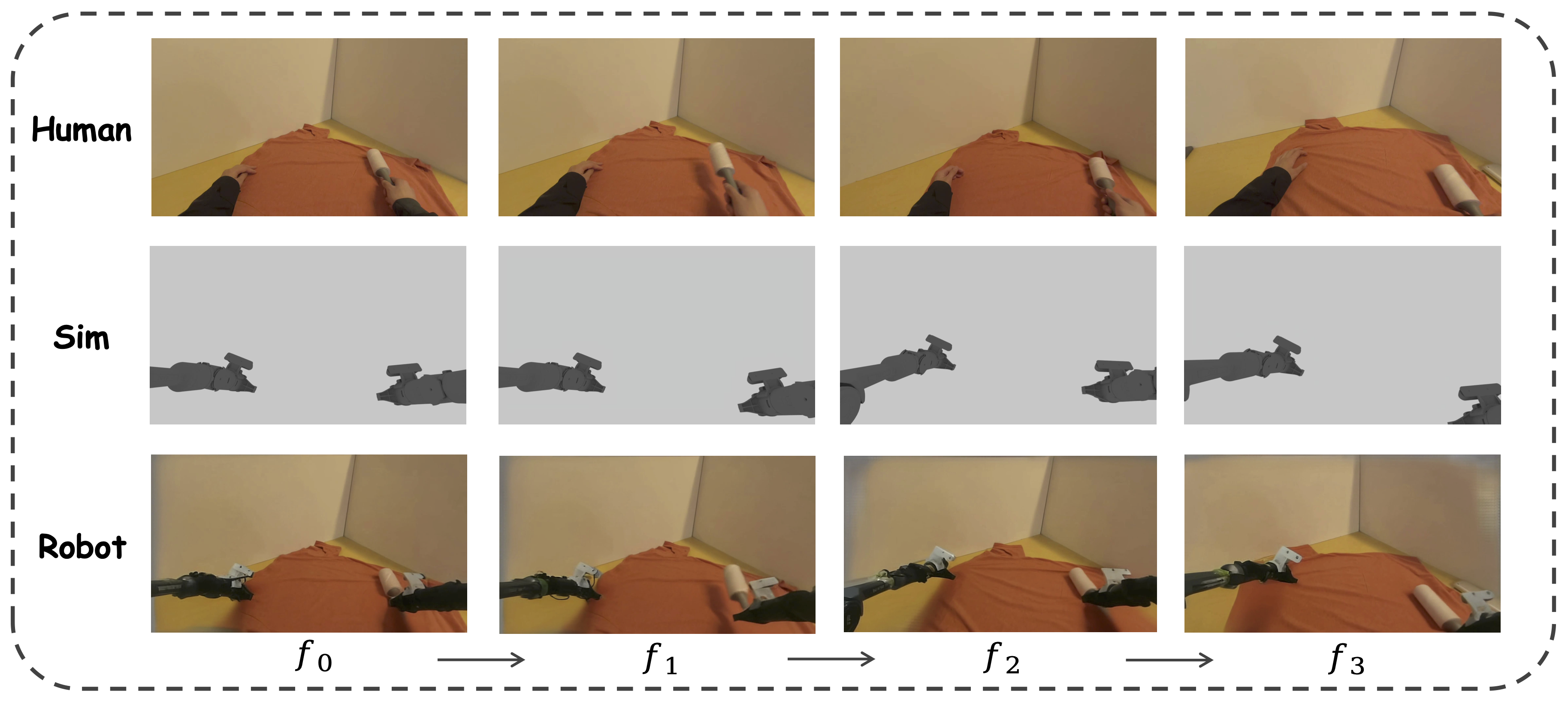
Overview of MimicDreamer. Viewpoint branch (top left): egocentric videos are stabilized by EgoStabilizer (warp perspective + background inpainting) to produce stable egocentric videos. Camera intrinsics/extrinsics and the robot URDF drive sim rendering to generate additional stable ego views. Action branch (bottom left): 3D hand trajectories are converted to robot actions with IK solver. Visual alignment (right): H2R Aligner learns to bridge the human-to-robot visual gap using stable egocentric videos and simulation robot videos. The resulting synthesized robot videos and robot actions are used for VLA training.
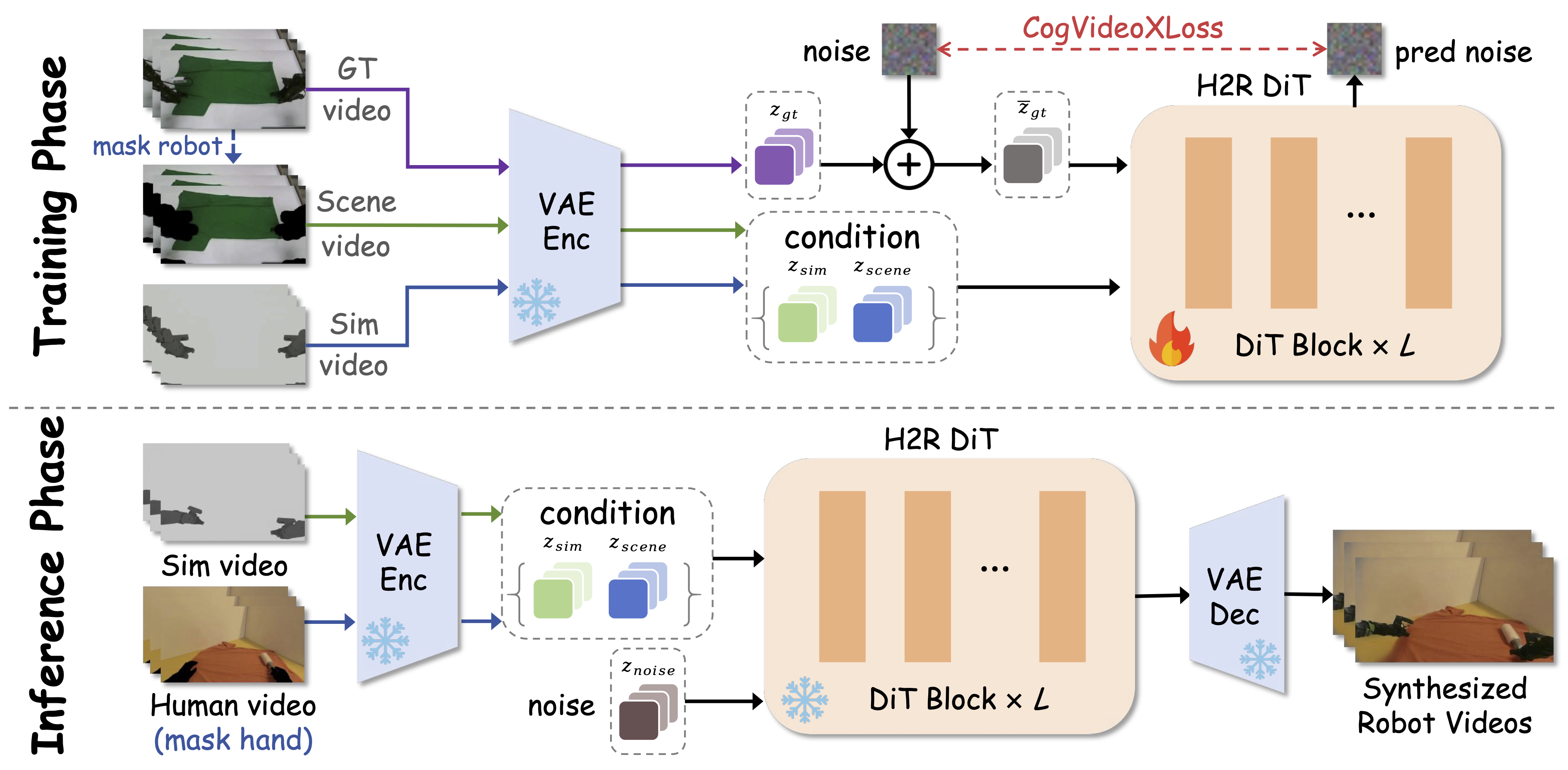
H2R Aligner. During training, the real robot video Vgt, background Vscene, and simulated foreground Vsim are encoded by a frozen VAE and channel-concatenated as [z̃tar, zscene, zsim] before entering the trainable H2R DiT, optimized with CogVideoXLoss loss. During inference, a hand-masked human background and IK-replayed simulation serve as conditions; the target starts from noise, is denoised by H2R DiT, and decoded by the frozen VAE into synthesized robot videos.